Cloud
Success in cloud computing migration.
Infrastructure Modernization
Reliable and profitable
Reduce costs optimizing resources by choosing different storage types according your data and costs, and increase resources any time your business need it.
We reduce the Cloud migration impacts so you can get all the benefits of an infrastructure modernization:
- Migration from Data Warehouse to Big Query
- Migration of workloads and/or data from an on-premises environment to the Cloud
- SQL database migration
High Performance Computing
Automation and resources optimization
The cloud manages the infrastructure as a service, reducing costs and routine task operations. At PUE, we bet for the implementation of full stack architectures with CI/CD applied to the processes automation for Infrastructure and Development, as well as container-based microservice architectures that allows resource consumption optimization and automatic scalability of services based on workload demand.
Data Analytics
Data-driven decisions
We design and create Data Lakes connecting data from different sources, which allows to process information, analyze data in real time and visualize the updated results that will provide you valuable information for decisions making.
Machine Learning & AI
Data insights
We use the data to implement ML & AI models with the Google Cloud suite of services (Vertex AI), to help companies optimize their business, get a better understanding of their customers, prevent risks and save time with disruptive and trained models.
Reduce costs optimizing resources by choosing different storage types according your data and costs, and increase resources any time your business need it.
We reduce the Cloud migration impacts so you can get all the benefits of an infrastructure modernization:
- Migration from Data Warehouse to Big Query
- Migration of workloads and/or data from an on-premises environment to the Cloud
- SQL database migration
The cloud manages the infrastructure as a service, reducing costs and routine task operations. At PUE, we bet for the implementation of full stack architectures with CI/CD applied to the processes automation for Infrastructure and Development, as well as container-based microservice architectures that allows resource consumption optimization and automatic scalability of services based on workload demand.
We design and create Data Lakes connecting data from different sources, which allows to process information, analyze data in real time and visualize the updated results that will provide you valuable information for decisions making.
We use the data to implement ML & AI models with the Google Cloud suite of services (Vertex AI), to help companies optimize their business, get a better understanding of their customers, prevent risks and save time with disruptive and trained models.
Infrastructure proposal

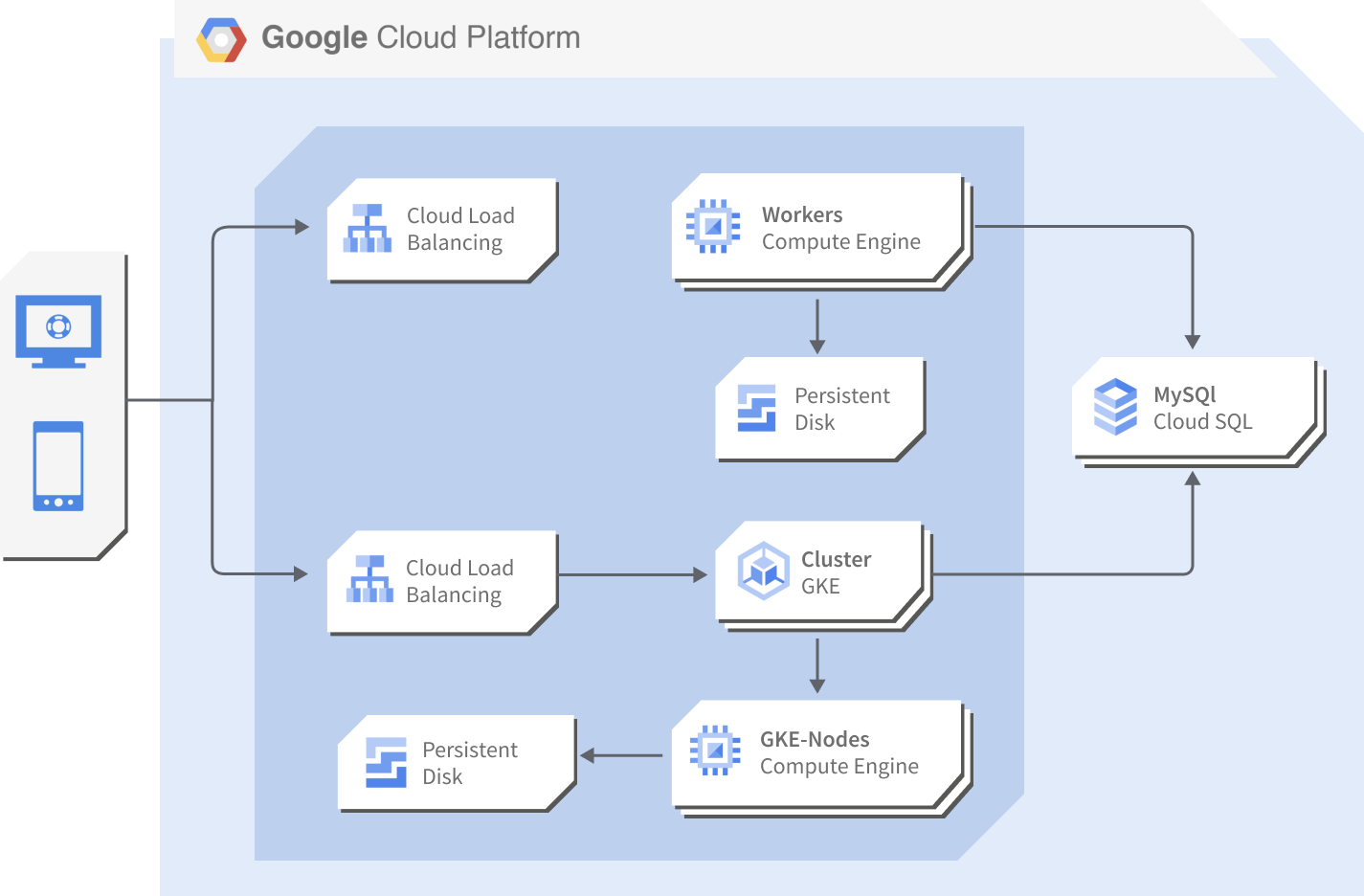
Use Case:
Containers on GKE & Hosts on Compute Engine

Data analytics project on Google Cloud microservices infrastructure

Objetives

- Evolve a platform from B2C to B2B.
- Have two clusters, one productive and one pre-productive with contingency capabilities in a Public Cloud environment based on Google Cloud.
- Develop the functionalities of the project.
- Solution support to cover the entire Big Data lifecycle.
Google Cloud environment
The solution proposes the use of Google's project infrastructure, which primarily features the components:
- Compute Engine
- Google Kubernetes Engine
- Cloud Storage
- Cloud SQL
- VPC Network
Instance types
For the creation of two fully interchangeable pre- and pro-differentiated environments, two independent environments identical in infrastructure are proposed to fulfil contingency functions. Each environment consists of the following components:
- 3 Master Nodes
- 6 Worker nodes

The recommended distribution of services and types of instances are:
|
Services |
Master Nodes |
Worker Nodes |
|---|---|---|
|
MapReduce |
N1-highmem-8 |
N1-highmem-8 |
|
HBase |
N1-highmem-8 |
N1-highmem-8 |
|
All CDH |
N1-highmem-8 |
N1-highmem-8 |
Google Kubernetes Engine
For client processes, GKE microservices are used with the following features:
- 2 clusters: pre-production and production.
- 2 instance templates, one for each cluster.
- Types of nodes running in the clusters: n1-standard-1.
Service architecture


Data analysis phase
Storage layer
|
Type |
Component |
Description |
|---|---|---|
|
Main |
HDFS |
Distributed storage system, core for all other systems and processing |
|
Main |
HBAse |
Columnar database for low-latency, scalable access to non-random data |
|
Optional |
KUDU |
Intermediate performance database between HBase and HDFS |
|
Main |
Parquet |
Columnar storage format on top of HBase and with possibility of compression |
|
Main |
Avro |
HDFS information container that allows the compression and metadata storage of the available information schema. |

Data entry phase
|
Input |
Access |
Description |
|---|---|---|
|
Syslog TCP |
Syslog TCP Source in Flume and Kafka |
Flume will be used for the receipt of information with a TCP listening source |
|
Files in local/ |
Spool Source at Flume and Kafka |
Flume will be used for pooling new information in parameterised directories |
|
Relational databases |
Sqoop |
Sqoop handles both full and incremental ingestion of structured SQL sources. |
|
Web Services |
HTTP Source in Flume and JSON Handler and Kafka |
A connector to web services with JSON content handling will be used |
Data processing phase
|
Requirement |
Component |
Description |
|---|---|---|
|
Batch processing |
Spark |
Highly effective in-memory processing of complete datasets |
|
Real-Time Processing |
Spark Streaming |
Micro-batch processing within time windows |
|
Filtering, Transformation, Bundling and Enrichment |
Spark Streaming, Spark SQL HBase |
Spark Streaming in conjunction with Spark SQL (facilitating process coding) for filtering options. HBase for low latency access to databases in order to exploit transformation and enrichment functions |
|
Process Analytics and Machine Learning |
MLlib, GraphX |
Spark processes that use the Machine Learning libraries |
|
Text indexing, aggregation and time series |
SolR |
SolR allows indexing of documents for subsequent agile search even in visual environments (integration with Hue for exploitation) |
|
Near Real-Time Decision Making |
Spark |
Design of a rule engine for low latency micro-batch decision making and performance |
|
Data Compression |
Avro and Parquet |
Enable reading and writing alongside native processing of compressed data |
Data exploitation phase
|
Requirement |
Module |
Description |
|---|---|---|
|
Visual Environment |
HUE |
Hue is the unified environment for the exploitation of data, it allows to connect visually with all the components of the cluster and to carry out the necessary processes in a visual and intuitive environment |
|
SQL-Like Queries |
Hive/Impala |
Hive is the standard query engine. Impala is included as a low latency engine to improve query response times. |
|
Third Party Integration |
ODBC/ WebServices/ Sqoop |
The connection can be made via JDBC/ODBC connections for reading data with Hive, or via WebServices such as HBase and dumping data into external databases via Sqoop |