
Tener una visualización de las aplicaciones que están corriendo en un clúster de Big Data, es de vital importancia para conocer el estado y la evolución de las mismas. Para ello, existen diferentes formas de monitorizar: en el caso de Cloudera se puede visualizar con Cloudera Manager o existe también la opción Webui de Yarn.
El problema de estas opciones es que la información no se almacena de manera infinita, siendo imposible visualizar grandes históricos. También, estas interfaces ofrecen un mínimo nivel de personalización, dificultando la motorización de las aplicaciones.
La solución es integrar las métricas de las aplicaciones con Solr más Grafana. Pero Grafana no sabe leer de SOLR, o ¡no sabía! Desde PUE hemos desarrollado un datasource de SOLR para añadir esa funcionalidad a Grafana permitiendo la representación de series temporales almacenadas. Esta solución ofrece la posibilidad de tener datos históricos ilimitados para evaluar la evolución de las aplicaciones o para la toma de decisiones que aporten valor al negocio, y además personalizable.
En éste artículo, ejemplificaré un caso de uso para personalizar la monitorización de métricas en Solr mediante Grafana para aplicaciones Apache Spark, aunque se puede desarrollar una monitorización de otros servicios como HDFS.
Pero antes de ir al ejemplo, veamos los siguientes conceptos:
¿Qué es Grafana?
Es un software libre incluido dentro de la fundación Apache que permite la visualización de datos a través de series temporales.
¿Qué es Solr?
Es un motor de búsqueda de código abierto, también incluido en la fundación Apache, que permite la indexación de datos.
Caso de uso: Monitorización de aplicaciones Apache Spark
Éste es un ejemplo sencillo, pero un caso de uso puede alcanzar una gran complejidad atacando a las diferentes interfaces anteriormente mencionadas.
Para nuestro ejemplo vamos a recuperar desde la API de Cloudera Manager un json y así obtener el número de aplicaciones que hay corriendo.
Una vez recopilada la información, se guarda en una colección de Solr.
Esta misma consulta se podría hacer directamente desde Grafana al Cloudera Manager con otro plugin, pero vamos a almacenarlas en Solr para no perder el histórico de métricas, debido a que en Cloudera Manager se pierde el histórico.
Para realizar la prueba nos hemos instalado Grafana en local junto con el plugin creado por PUE https://github.com/pueteam/datasource-plugin-Solr y hemos levantado un docker de Solr 7.7.1.
Para recuperar el número de aplicaciones vamos a hacer una consulta a la API (/api/v19/clusters/cluster/services/yarn/yarnApplications) la cual nos devuelve un json.
Este json tiene un formato que se divide por applications y luego cada aplicación tiene sus diferentes valores (name, startTime,user…).
Pero para nuestro ejemplo solo vamos a contar el número de aplicaciones y los vamos a guardar en Solr junto con otro campo, que es el que corresponde con el momento de realizar esa consulta.
Para ello hemos hecho un script de Python que hace la consulta a la API y luego a través de pySolr metemos los datos a nuestra colección (https://github.com/django-haystack/pySolr).
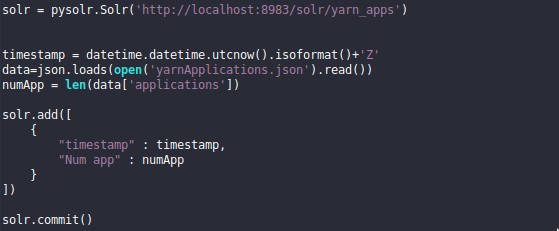
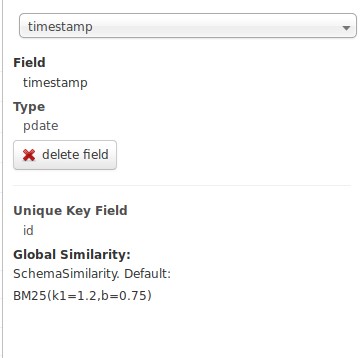
Para que Grafana pueda utilizar el campo timestamp y representar los datos en la línea temporal, esté tiene que ser del tipo pdate en Solr, si es de cualquier otro formato no lo reconocerá Grafana:
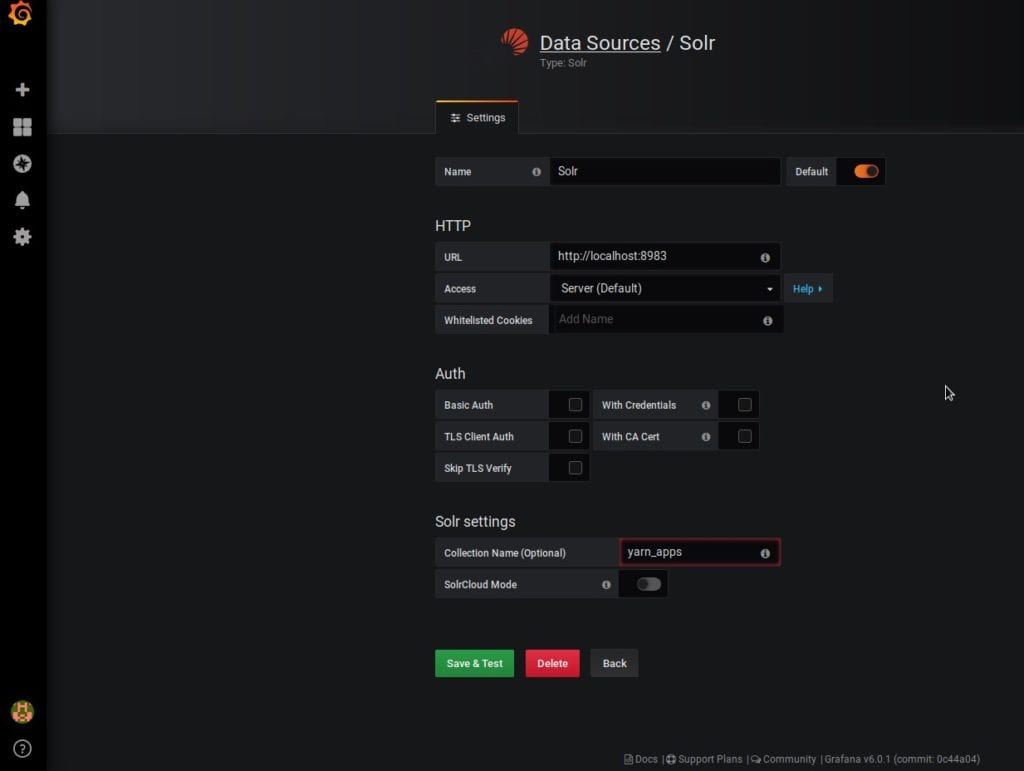
Una vez que hemos creado la colección en Solr y hemos metido datos pasamos a configurar el datasource de Grafana, en este caso tenemos nuestro Solr en localhost:8983 y nuestra colección con las métricas (yarn_apps)
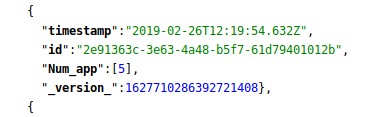
Los datos que hemos ido metiendo en nuestra colección de Solr tienen los siguientes campos:
- timestamp: El valor del momento en el que se obtiene la métrica.
- Num_app: El número de aplicaciones que están corriendo al obtener la métrica.
- id: Campo obligatorio para Solr ya que cada documento en Solr tiene que tener un id único.
- _version_ : Un campo interno para Solr cloud y la actualización de los documentos.
Quedando cada documento en la colección de la siguiente forma:
Conociendo esta información procedemos a configurar los diferentes parámetros en nuestro Dashboard. En este caso hemos creado tres paneles. El primero muestra en una gráfica todas las aplicaciones que van corriendo a lo largo del tiempo:
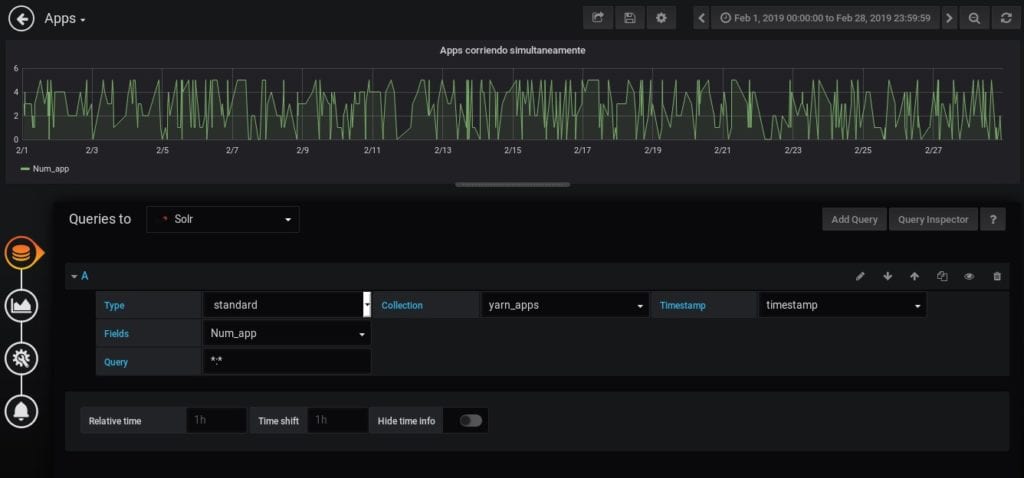
El segundo panel creado es donde vamos a ver el número máximo de aplicaciones que se han ejecutado simultáneamente hoy. Por último, el tercer panel, con el número máximo de aplicaciones que se han ejecutado a la vez en el periodo de tiempo que está mostrando en el Dashboard.
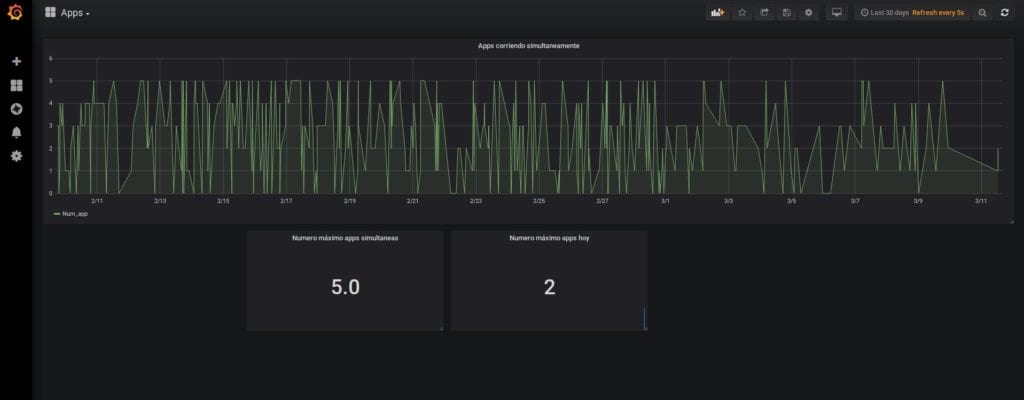
Para mostrar el número máximo de aplicaciones de hoy hay que hacer una subconsulta dentro de la query que hace Grafana. Esto solo funciona si el periodo elegido incluye el día actual, ya que sí no se realiza de esta forma la primera consulta excluye este periodo y obtenemos 0 registros.
La configuración sería la siguiente:
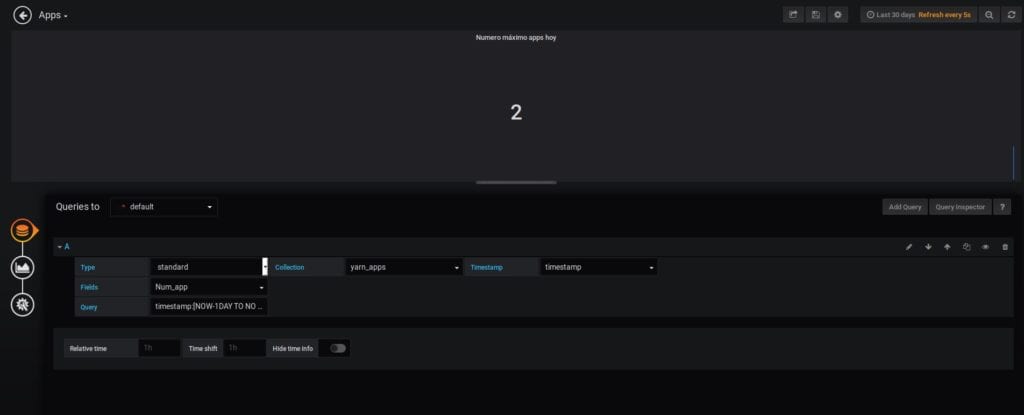
“El campo query tiene el siguiente valor: timestamp:[NOW-1DAY TO NOW]”
Y esté sería un ejemplo práctico de un uso del plugin desarrollado por PUE para poder hacer consultas a una colección de Solr desde Grafana.
Enlaces de interés

Sobre mí:
Desde pequeño cuando me regalaron mi primer ordenador, siempre he estado pegado él. Me apasiona el poder de la tecnología y su capacidad de transformarnos, por ello me he formado en diferentes tecnologías dentro de la informática, hasta que descubrí el potencial del Big Data. Desde entonces me he especializado en administrar plataformas, un reto apasionante en el mundo de los datos.


Sobre PUE
Como líder de Big Data, Cloud, Microservicios, NoSQL y DevOps en España, el objetivo de PUE es, siempre, ofrecer a sus clientes las mejores soluciones con las últimas tecnologías: soluciones innovadoras propuestas por un equipo técnico certificado, expertos en Administración, Analista de Datos, Científico de Datos y Desarrollo.
Para más información sobre los servicios de PUE:
Servicios y soluciones con PUE
Formación y certificación oficial
Contacta para saber más en:
![]() consulting@pue.es
consulting@pue.es ![]() Solicitud de información para la implantación de proyectos
Solicitud de información para la implantación de proyectos


